|
I am a ML engineer at Waymo Perception working on multi-modal (image, video, text) foundation models for self-driving. I received my Ph.D. in Computational and Mathematical Engineering (ICME) from Stanford University where I was advised by Prof. Serena Yeung. I am broadly interested in computer vision and machine learning. My PhD research was focused on human-centric 3D perception and generative models. I interned at Waymo Research where I worked on human-centric representation learning from LiDAR data, as well as Adobe Research where I worked on generalizable single-view human NeRF prediction. Prior to my Ph.D, I received B.S. in Computer Science and B.S. in Mathematics from Carnegie Mellon University. I also previously worked as a Research Engineer for a fund manager on the East Coast, on large-scale backtesting and portfolio optimization services. Email / Linkedin / Twitter / Google Scholar |
|
|
|
Jan, 2025: Research article "Artificial Intelligence-Powered 3D Analysis of Video-Based Caregiver-Child Interactions" accepted to Science Advances.
|
|
|
 |
Zhenzhen Weng, Jingyuan Liu, Hao Tan, Zhan Xu, Yang Zhou, Serena Yeung-Levy, Jimei Yang Preprint | Website Reconstructing 3D humans from a single image has been extensively investigated. However, existing approaches often fall short on capturing fine geometry and appearance details, hallucinating occluded parts with plausible details, and achieving generalization across unseen and in-the-wild datasets. We present Human-LRM, a diffusion-guided feed-forward model that predicts the implicit field of a human from a single image. Leveraging the power of the state-of-the-art reconstruction model (i.e., LRM) and generative model (i.e Stable Diffusion), our method is able to capture human without any template prior, e.g., SMPL, and effectively enhance occluded parts with rich and realistic details. |
 |
Zhenzhen Weng, Laura Bravo, Serena Yeung 3DV 2024 (Spotlight) | Website | Code Recent text-to-image generative models such as Stable Diffusion often struggle to preserve plausible human structure in the generations. We propose Diffusion model with Human Pose Correction (Diffusion-HPC), a method that generates photo-realistic images with plausible posed humans by injecting prior knowledge about human body structure. The generated image-mesh pairs are well-suited for downstream human mesh recovery task. |
 |
Zhenzhen Weng, Zeyu Wang, Serena Yeung Preprint | Website We present ZeroAvatar, a method that introduces the explicit 3D human body prior to the optimization process. We show that ZeroAvatar significantly enhances the robustness and 3D consistency of optimization-based image-to-3D avatar generation, outperforming existing zero-shot image-to-3D methods. |
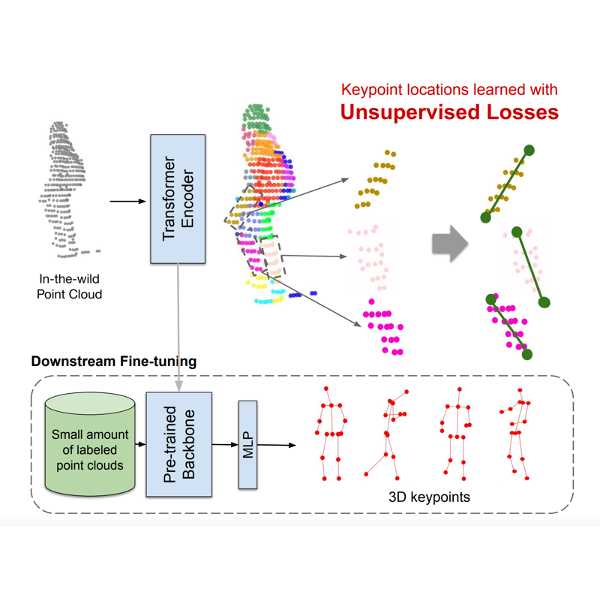 |
Zhenzhen Weng, Alexander S. Gorban, Jingwei Ji, Mahyar Najibi, Yin Zhou, Dragomir Anguelov Conference on Computer Vision and Pattern Recognition (CVPR), 2023 Paper | Project We propose GC-KPL - Geometry Consistency inspired Key Point Leaning. By training on the large WOD training set without any annotated keypoints, we attain reasonable performance as compared to the fully supervised approach. Further, the backbone benefits from the unsupervised training and is useful in downstream fewshot learning of keypoints, where fine-tuning on only 10 percent of the labeled training data gives comparable performance to fine-tuning on the entire set. |
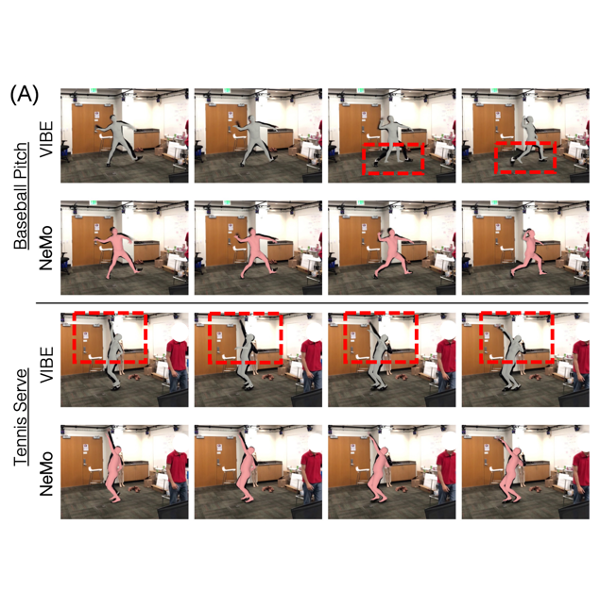 |
Kuan-Chieh Wang, Zhenzhen Weng, Maria Xenochristou, Joao Pedro Araujo, Jeffrey Gu, C. Karen Liu, Serena Yeung Conference on Computer Vision and Pattern Recognition (CVPR) (Highlight), 2023 Paper | Website We aim to bridge the gap between monocular HMR and multi-view MoCap systems by leveraging information shared across multiple video instances of the same action. We introduce the Neural Motion (NeMo) field. It is optimized to represent the underlying 3D motions across a set of videos of the same action. |
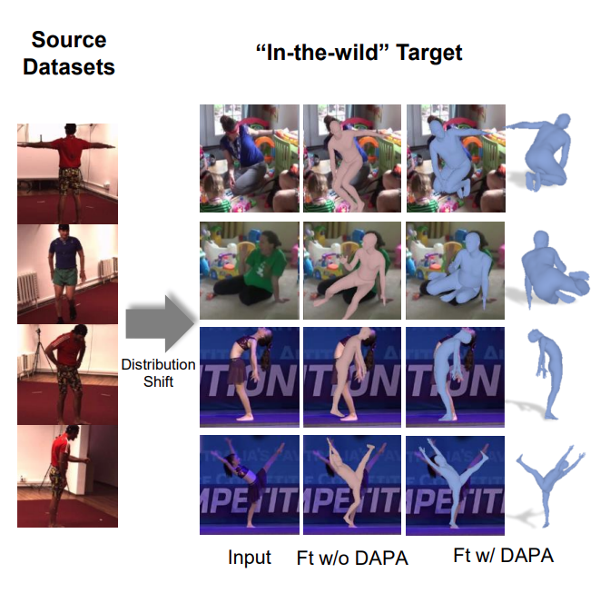 |
Zhenzhen Weng, Kuan-Chieh (Jackson) Wang, Angjoo Kanazawa, Serena Yeung International Conference on 3D Vision (3DV), 2022 Paper | Project Page | Code We propose Domain Adaptive 3D Pose Augmentation (DAPA), a data augmentation method that combines the strength of methods based on synthetic datasets by getting direct supervision from the synthesized meshes. |
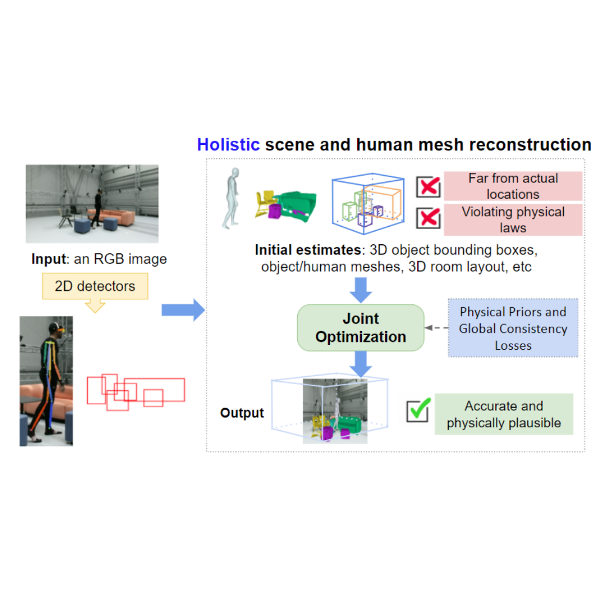 |
Zhenzhen Weng, Serena Yeung Conference on Computer Vision and Pattern Recognition (CVPR), 2021 Paper We propose a holistically trainable model that perceives the 3D scene from a single RGB image, estimates the camera pose and the room layout, and reconstructs both human body and object meshes. |
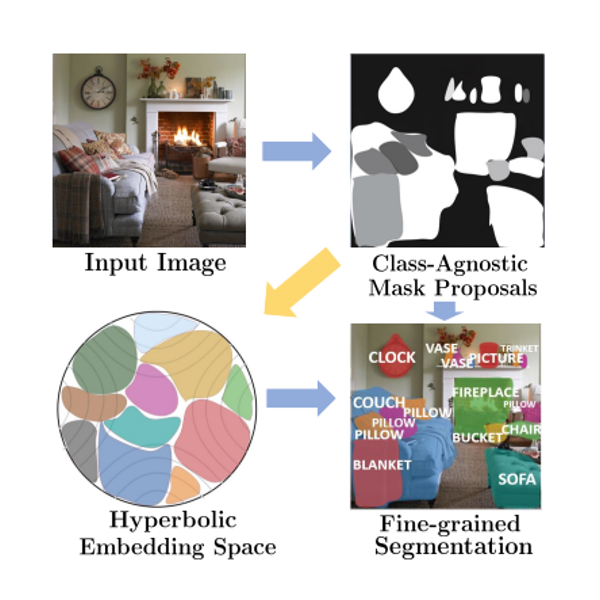 |
Zhenzhen Weng, Mehmet Giray Ogut, Shai Limonchik, Serena Yeung Conference on Computer Vision and Pattern Recognition (CVPR), 2021 Paper We propose a method that can perform unsupervised discovery of long-tail categories in instance segmentation, through learning instance embeddings of masked regions. |
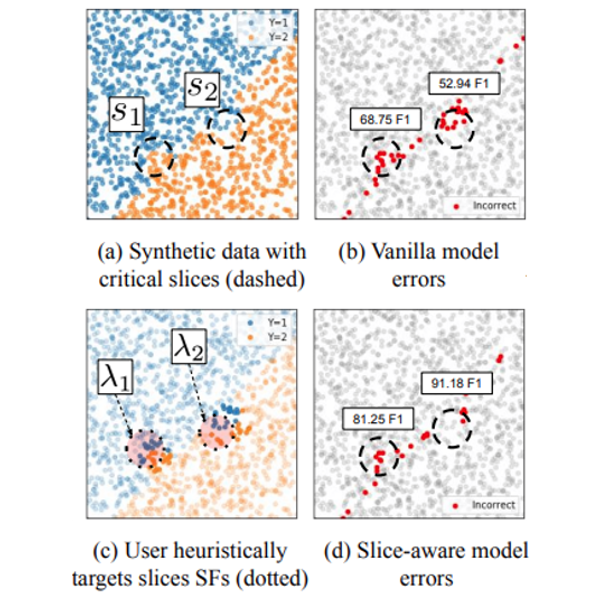 |
Vincent S Chen, Sen Wu, Zhenzhen Weng, Alexander Ratner, Christopher Ré The Conference and Workshop on Neural Information Processing Systems (NeurIPS), 2019 Paper We introduce the challenge of improving slice-specific performance without damaging the overall model quality, and proposed the first programming abstraction and machine learning model to support these actions. |
 |
Zhenzhen Weng, Paroma Varma, Alexander Masalov, Jeffrey Ota, Christopher Ré IEEE Intelligent Vehicles Symposium (IEEE IV), 2019 Paper We introduced weak supervision heuristics as a methodology to infer complex objects and situations by combining simpler outputs from current, state-of-the art object detectors. |
|
|
|
Research Scientist Intern @ Adobe Research, San Jose, CA, Jun - Sept, 2023
|

|
Webpage template and source code from Jon Barron. |